您现在的位置是:首页 > 科技 >正文
英特尔的第三代至强可扩展CPU提供16位FPU处理
发布时间:2021-12-17 10:05:56方秋威来源:
英特尔今天宣布了其第三代至强可扩展(即金牌和白金)处理器,以及新一代 Optane 持久内存(读作:极低延迟、高耐用性 SSD)和 Stratix AI FPGA 产品。
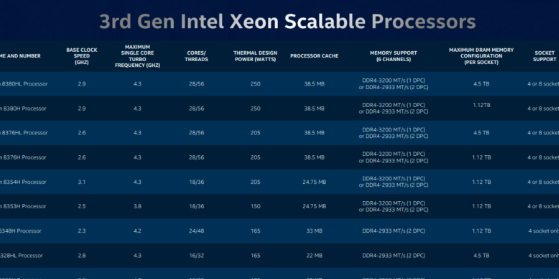
AMD 目前在除硬件加速 AI之外的几乎所有可以想象的性能指标上都击败英特尔这一事实 在这一点上并不是新闻。这对英特尔来说显然也不是新闻,因为该公司没有对至强可扩展与竞争 Epyc Rome 处理器的性能做出任何声明。更有趣的是,英特尔根本没有提到通用计算工作负载。
找到对显示的唯一非 AI 代际改进的解释需要跳过多个脚注。有了足够的决心,我们最终发现概述幻灯片中提到的“平均性能提升 1.9 倍”指的是“估计或模拟的”SPECrate 2017 基准,将四路 Platinum 8380H 系统与五年前的四路系统进行比较E7-8890 v3。
公平地说,英特尔似乎确实在人工智能领域引入了一些令人印象深刻的创新。“Deep Learning Boost”以前只是 AVX-512 指令集的品牌,现在也包含全新的 16 位浮点数据类型。
凭借前几代 Xeon Scalable,英特尔率先并大力推动使用 8 位INT8整数——推理处理及其 OpenVINO 库。对于推理工作负载,英特尔认为INT8在大多数情况下较低的准确度是可以接受的,同时提供推理管道的极端加速。然而,对于训练,大多数应用程序仍然需要更高的FP3232 位浮点处理精度。
新一代增加了 16 位浮点处理器支持,英特尔称之为bfloat16. 将FP32 模型的位宽减半会加速处理本身,但更重要的是,将模型保存在内存中所需的 RAM 减半。对于使用FP32 模型的程序员和代码库来说,利用新数据类型也比转换为整数更简单。
Intel 还贴心地提供了一个 围绕 BF16 数据类型效率的游戏。我们不能推荐它作为游戏或教育工具。
傲腾存储加速
英特尔还宣布推出速度提高 25% 的新一代 Optane“持久内存”固态硬盘,可用于大大加速人工智能和其他存储管道。Optane SSD 在3D Xpoint技术上运行,而不是 NAND 闪存 典型的 SSD。与 NAND 相比,3D Xpoint 具有更高的写入耐久性和更低的延迟。更低的延迟和更高的写入耐久性使其作为一种快速缓存技术特别有吸引力,它甚至可以加速所有固态阵列。
这里最大的收获是 Optane 的极低延迟允许加速 AI 管道——这通常是存储瓶颈——通过提供对太大而无法完全保存在 RAM 中的模型的非常快速的访问。对于涉及快速、繁重写入的管道,Optane 缓存层还可以通过减少必须实际提交给它的写入总数来显着增加其下方 NAND 主存储的预期寿命。
延迟与 IOPS,读/写工作负载为 70/30。 橙色和绿色线是数据中心级传统NAND SSD; 蓝线是傲腾。
放大 /延迟与 IOPS,读/写工作负载为 70/30。橙色和绿色线是数据中心级传统NAND SSD;蓝线是傲腾。
汤姆的硬件
例如,256GB Optane 具有360PB写入耐久性规格,而三星 850 Pro 256GB SSD 仅具有150TB耐久性的规格——比 Optane 具有 1,000:1 的优势。
同时,这篇 来自 2019 年的出色 Tom's Hardware评论展示了 Optane 在延迟方面与传统数据中心级 SSD 相比还有多远。
Stratix 10 NX FPGA
最后,英特尔发布了其 Stratix FPGA 的新版本。场门可编程阵列可用作某些工作负载的硬件加速,允许更多通用 CPU 内核处理 FPGA 无法处理的任务。
标签:
猜你喜欢
最新文章
- 聚酯纤维100%的衣服怎么洗(100%聚酯纤维怎么洗)
- 广东省过渡性养老金是在哪一年截止 2022广州市过渡性养老金怎么计算的
- 2022年02月22日积灰问题难消除FindX或成“吸尘机”
- little和less有什么区别(less和little的区别)
- 鞍钢职工养老保险查询 2022鞍山养老保险查询途径有哪些
- ow是哪国的(macow 是哪个国家)
- 奥迪A4L入门版将于9月上市 搭载1.4T发动机
- 1月15日魅族16真机再曝光18:9屏幕+超窄边框
- new bunren是正品吗(new caledonia是哪个国家)
- 黑龙江省鸡西市养老保险今年交多少? 2022鸡西养老保险查询指南
- pizza纸盒能进微波炉吗(pizza纸盒能进微波炉吗)
- 2021成都车展博物馆:瑞丰S2S3智能驱动系列
- 井矿盐跟海盐哪种好(井矿盐和海盐区别)
- 2022年02月22日小米&美图重磅联姻网友火速放出渲染图
- 丹霞石有什么特点(丹霞石是什么石头)
- 两河流域代表的是什么文明(两河流域文明是指什么)
- 已有27队晋级世界杯
- 世预赛巴西与玻利维亚双方的首发阵容
- 德国客场1比1战平荷兰
- 阿根廷客场对阵厄瓜多尔的首发名单
- 范迪克首发踢满全场
- 葡萄牙2比0战胜北马其顿
- 博格巴替补上场送出助攻
- 斯卡洛尼表示我希望阿圭罗能在队友们身边